
I’ve been learning Rust for the past twenty days or so, working through the Blandy & Orendorff book, coding up things as I go. Once I got into playing with Rust traits and closures and associated types, the similarities to programming in Haskell with typeclasses, data structures, closure passing and associated types was pretty obvious.
As a warm up I thought I’d try porting the stream fusion core from Haskell to Rust. This was code I was working on more than a decade ago. How much of it would work or even make sense in today’s Rust?
Footnote: this is the first code I’ve attempted to seriously write for more than 2 years, as I’m diving back into software engineering after an extended sojourn in team building and eng management. I was feeling a bit .. rusty. Let me know if I got anything confused.
TLDR
- Two versions of the basic stream/list/vector APIs: a data structure with boxed closure-passing and pure state
- And a more closure-avoiding trait encoding that uses types to index all the code statically
Fun things to discover:
- most of the typeclass ‘way of seeing’ works pretty much the same in Rust. You index/dispatch/use similar mental model to program generically. I was able to start guessing the syntax after a couple of days
- it’s actually easier to get first class dictionaries and play with them
- compared to the hard work we do in GHC to make everything strict, unboxed and not heap-allocated, this is the default in Rust which makes the optimization story a lot simpler
- Rust has no GC , instead using a nested-region like allocation strategy by default. I have to commit to specific sharing and linear memory use up front. This feels a lot like an ST-monad-like state threading system. Borrowing and move semantics take a bit of practice to get used to.
- the trait version looks pretty similar to the core of the standard Rust iterators, and the performance in toy examples is very good for the amount of effort I put in
- Rust seems to push towards method/trait/data structure-per-generic-function programming, which is interesting. Encoding things in types does good things, just as it does in Haskell.
- Non-fancy Haskell, including type class designs, can basically be ported directly to Rust, though you now annotate allocation behavior explicitly.
- cargo is a highly polished ‘cabal’ with lots of sensible defaults and way more constraints on what is allowed. And a focus on good UX.
As a meta point, it’s amazing to wander into a fresh programming language, 15 years after the original “associated types with class” paper, and find basically all the original concepts available, and extended in some interesting ways. There’s a lot of feeling of deja vu for someone who worked on GHC optimizations/unboxing/streams when writing in Rust.
Version 1: direct Haskell translation
https://github.com/donsbot/experiments-rust/blob/master/stream-fusion/src/closure.rs
First, a direct port of the original paper. A data type for stepping through elements of stream, including ‘Skip’ so we can filter things. And a struct holding the stream stepper function, and the state. Compared to the Haskell version (in the comment) there’s more rituals to declare what goes on the heap, and linking the lifetime of objects together. My reward for doing this is not needing a garbage collector. There’s quite an enjoyable serotonin reward when a borrow checking program type checks :-)
You can probably infer from the syntax this will be operationally expensive: a closure boxed up onto the heap. Rust’s explicit control of where things are stored and for how long feels a lot like a type system for scripting allocators, and compared to Haskell you’re certainly exactly aware of what you’re asking the machine to do.
Overall, its a fairly pleasing translation and even though I’m putting the closure on the heap I’m still having it de-allocated when the stream is dropped. Look mum, closure passing without a GC.

We can create empty streams, or streams with a single element in them. Remember a stream is just a function from going from one value to the next, and a state to kick it off:
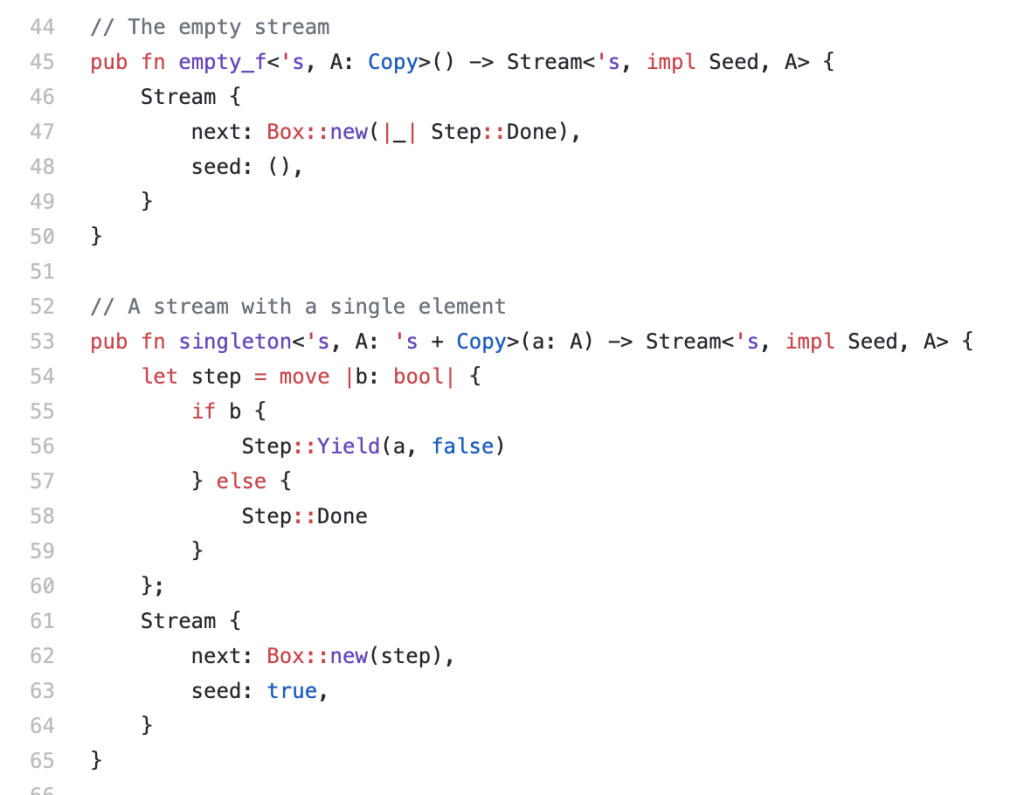
The lambda syntax feels a bit heavy at first, but you get used to it. The hardest part of these definitions were:
- being explicit about whether my closure was going to borrow or own the lifetime of values it captures. Stuff you never think about in Haskell, with a GC to take care of all that thinking (for a price). You end up with a unique type per closure showing what is captured, which feels _very_ explicit and controlled.
- no rank-2 type to hide the stream state type behind. The closest I could get was the ‘impl Seed’ opaque return type, but it doesn’t behave much like a proper existential type and tends to leak through the implementation. I’d love to see the canonical way to hide this state value at the type level without being forced to box it up.
- a la vector ‘Prim’ types in Haskell, we use Copy to say something about when we want the values to be cheap to move (at least, that’s my early mental model)
I can generate a stream of values, a la replicate:

As long as I’m careful threading lifetime parameters around I can box values and generate streams without using a GC. This is sort of amazing. (And the unique lifetime token-passing discipline feels very like the ST monad and its extensions into regions/nesting). Again , you can sort of “feel” how expensive this is going to be, with the capturing and boxing to the heap explict. That boxed closure dynamically invoked will have a cost.
Let’s consume a stream, via a fold:
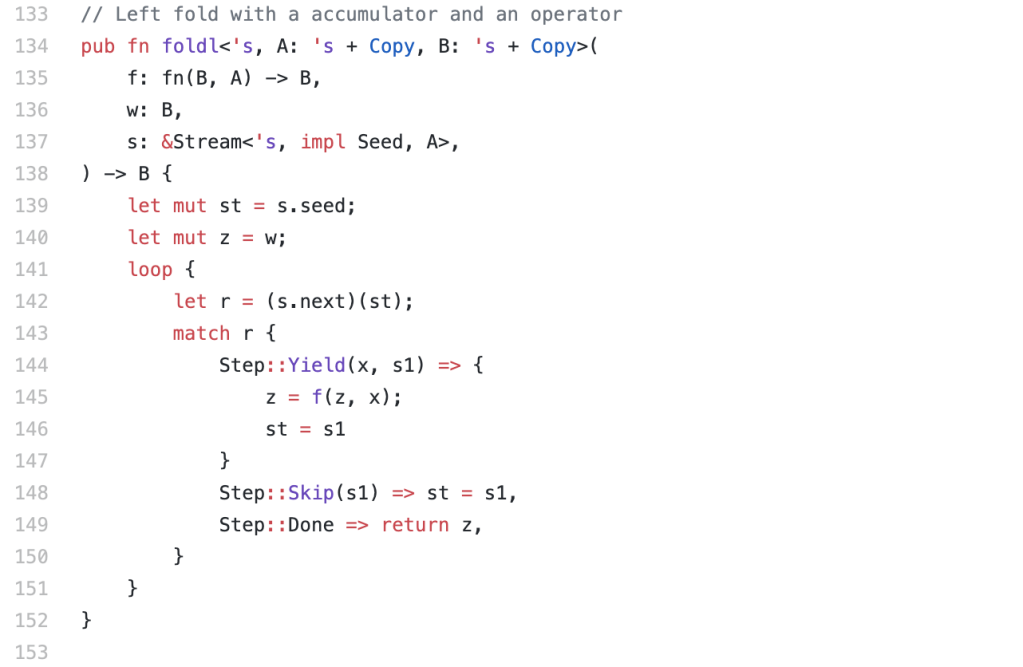
Not too bad. The lack of tail recursion shows up here, so while I’d normally write this as a ‘go’ local work function with a stack parameter, to get a loop, instead in Rust we just write a loop and peek and poke the memory directly via a ‘mut’ binding. Sigh, fine, but I promise I’m still thinking in recursion.
Now I can do real functional programming:

What about something a bit more generic: enumFromTo to fill a range with consecutive integer values, of any type supporting addition?

The trait parameters feel a lot like a super layered version of the Haskell Num class, where I’m really picking and choosing which methods I want to dispatch to. The numeric overloading is also a bit different (A::one()) instead of an overloaded literal. Again, is almost identical to the Haskell version, but with explicit memory annotations, and more structured type class/trait hierarchy. Other operations, like map, filter, etc all fall out fairly straight forward. Nice: starting to feel like I can definitely be productive in this language.
Now I can even write a functional pipeline — equivalent to:
sum . map (*2) . filter (\n -> n`mod`2 == 1) $ [1..1000000::Int]
=> 500000000000
As barebones Rust:

It actually runs and does roughly what I’d expect, for N=1_000_000:
$ cargo run
500000000000
Another moment of deja vu, installing Criterion to benchmark the thing. “cargo bench” integration is pretty sweet:

So about 7 ms for four logical loops over 1M i64 elements. That’s sort of plausible and actually not to bad considering I don’t know what I’m doing.

The overhead of the dynamic dispatch to the boxed closure is almost certainly going to dominate, and and then likely breaks inlining and arithmetic optimization, so while we do get a fused loop, we get all the steps of the loop in sequence. I fiddled a bit with the inlining the consuming loop, which shaved 1ms off, but that’s about it.
A quick peek at the assembly f–release mode, which I assume does good things, and yeah, this isn’t going to be fast. Tons of registers, allocs and dispatching everywhere. Urk.

But it works! The first thing directly translated works, and it has basically the behavior you’d expect with explict closure calls. Not bad!
A trait API
https://github.com/donsbot/experiments-rust/blob/master/stream-fusion/src/trait.rs
That boxed closure bothers me a bit. Dispatching to something that’s known statically. The usual trick for resolving things statically is to move the work to the type system. In this case, we want to lookup the right ‘step’ function by type. So I’ll need a type for each generator and transformer function in the stream API. We can take this approach in Rust too.
Basic idea:
- move the type of the ‘step’ function of streams into a Stream trait
- create a data type for each generator or transformer function, then impl that for Stream. This is the key to removing the overhead resolving the step functions
- stream elem types can be generic parameters, or specialized associated types
- the seed state can be associated type-indexed
I banged my head against this a few different ways, and settled on putting the state data into the ‘API key’ type. This actually looks really like something we already knew how to do – streams as Rust iterators – Snoyman already wrote about it 3 years ago! — I’ve basically adapted his approach here after a bit of n00b trial and error.
The ‘Step’ type is almost the same, and the polymorphic ‘Stream’ type with its existential seed becomes a trait definition:

What’s a bit different now is how we’re going to resolve the function to generate each step of the stream. That’s now a trait method associated with some instance and element type.
So e.g. if I want to generate an empty stream, I need a type, and instance and a wrapper:

Ok not too bad. My closure for stepping over streams is now a ‘next’ method. What would have been a Stream ‘object’ with an embedded closure is now a trait instance where the ‘next’ function can be resolved statically.
I can convert all the generator functions like this. For example, to replicate a stream I need to know how many elements, and what the element is. Instead of capturing the element in a closure, it’s in an explicit data type:

The step function is still basically the same as in the Haskell version, but to get the nice Rust method syntax we have it all talk to ‘self’.
We also need a type for each stream transformer: so a ‘map’ is now a struct with the mapper function, paired with the underlying stream object it maps over.

This part is a bit more involved — when a map is applied to a stream element, we return f(x) of the element, and lift the stream state into a Map stream state for the next step.
I can implement Stream-generic folds now — again, since I have no tail recursion to consume the stream I’m looping explicitly. This is our real ‘driver’ of work , the actual loop pulling on a chain of ‘stream.next()’s we’ve built up.

Ok so with the method syntax this looks pretty nice:

I had to write out the types here to understand how the method resolving works. We build up a nice chain of type information about exactly what function we want to use at what type. The whole pipeline is a Map<Filter<Range < … type> , all an instance of Stream.

So this should do ok right? No boxing of closures, there could be some lookups and dispatch but there’s enough type information here to know all calls statically. I don’t have much intuition for how Rust will optimize the chain of nested Yield/Skip constructors.. but I’m hopeful given the tags fit in 2 bits, and I don’t use Skip anywhere in the specific program.

288 microseconds to collapse a 1_000_000 element stream. Or about 25x faster. Nice!

So the type information and commitment to not allocating to the heap does a lot of work for us here. I ask cargo rustc --bin stream_test --release -- --emit asm for fun. And this is basically what I want to see: a single loop, no allocation, a bit of math. Great.

It’s converted the %2 / *2 body into adding a straight i64 addition loop with strides. I suspect with a bit of prodding it could resolve this statically to a constant but that’s just a toy anyway. All the intermediate data structures are gone.
Overall, that’s a pretty satisfying result. With minimal effort I got a fusing iterator/stream API that performs well out of the box. The Rust defaults nudge code towards low overhead by default. That can feel quite satisfying.
 … In which I use genetic algorithms to search for optimal LLVM optimizer passes to make Haskell programs faster …
… In which I use genetic algorithms to search for optimal LLVM optimizer passes to make Haskell programs faster …

